I learned what an alarm flood actually looks like during a process upset on the offshore brownfield in Africa, around 2017. A compressor trip cascaded through the process — one alarm became three, three became fifteen, fifteen became forty-seven. By the time the operator had acknowledged the initial alarm, twenty more had stacked up.
The alarm summary screen was scrolling so fast that critical alarms were sliding off the visible area before anyone could read them. The operator did the right thing — followed his training, took the process to safe state — but he did it despite the alarm system, not because of it.
That experience changed how I think about alarm management. The alarm system isn’t there to tell the operator that something is wrong. The operator already knows something is wrong when the trip happens. The alarm system is there to tell the operator what specifically is wrong and what to do about it — and during a flood, it fails at exactly the moment when it’s needed most. ISA-18.2 exists to prevent that failure.
A few months later, the alarm rationalization workshop on that same project ran for three weeks. Operations, engineering, process safety, vendor specialists sitting in a conference room going through every alarm in the database — line by line, deciding what to keep, what to suppress, what to reclassify, what to retire.
Tedious doesn’t describe it. But by the end, the alarm system was dramatically better than it had been. The next process upset came months later, and the alarm flood that would have happened didn’t.
This guide is the practitioner explanation of ISA-18.2 I wish I’d had before that first workshop. I’ll walk through the alarm management lifecycle, the philosophy document, the rationalization process, alarm priorities, performance metrics, and how the standard integrates with ISA-101 HMI design and IEC 61511 safety. Written from sitting in rationalization workshops, watching alarm floods, and seeing what works.
If you’ve read our ISA-101 HMI Design guide, this article completes the companion standard pairing.
TL;DR — Quick Answer: What Is ISA-18.2?
ISA-18.2 (officially ANSI/ISA-18.2-2016, titled “Management of Alarm Systems for the Process Industries”) is the international standard that defines how industrial alarm systems should be designed, implemented, operated, and maintained throughout their lifecycle. The standard exists to prevent alarm floods, reduce nuisance alarms, and ensure that the alarm system actually helps operators during abnormal situations rather than overwhelming them.
The standard establishes a ten-stage lifecycle per the official ISA-18.2 standard (philosophy, identification, rationalization, detailed design, implementation, operation, maintenance, monitoring & assessment, management of change, audit) and requires a documented Alarm Philosophy that governs every aspect of alarm design at the facility.
ISA-18.2 was originally published in 2009 and revised in 2016. It became IEC 62682 internationally and is referenced as recognized good engineering practice by OSHA and other regulators. The standard applies to continuous, batch, and discrete processes across oil and gas, refining, petrochemicals, power generation, pharmaceuticals, and water treatment.
Key alarm management concepts:
- Alarm Philosophy — the foundational document governing all alarm design
- Rationalization — the process of reviewing every alarm against the philosophy
- Alarm priorities — Critical / High / Medium / Low with defined response expectations
- Performance metrics — alarm rate targets (~1 alarm per 10 minutes for normal operation)
- Alarm flood threshold — typically 10+ alarms/minute = flood condition
- Companion to ISA-101 HMI Design — alarm management defines alarms; ISA-101 displays them effectively
What You Will Learn
This guide covers alarm management at practitioner depth:
- What ISA-18.2 is, what it requires, and why it exists
- The ten-stage alarm management lifecycle and what happens at each stage
- The Alarm Philosophy document and what it contains
- The rationalization process — what alarm rationalization workshops actually look like
- Alarm priorities (Critical / High / Medium / Low) with real examples
- Performance metrics and targets (alarm rates, flood thresholds, response time)
- Alarm flooding — what causes it and how to prevent it
- How alarm management integrates with ISA-101 HMI design
- Implementation on Honeywell Experion, Yokogawa CENTUM, and Emerson DeltaV
- Common alarm management mistakes I’ve seen on real projects
What ISA-18.2 Is and Why It Exists
To understand the standard properly, you have to understand the operator alarm problem that drove its creation.
The alarm management problem before the standard.
Through the 1990s and into the 2000s, industrial alarm systems suffered from a consistent failure mode: too many alarms. As digital control systems made it easy to add alarm configuration, engineering teams added alarms liberally. Every process variable got a high alarm and a low alarm. Every analyzer got an out-of-range alarm. Every motor got a status alarm. Every valve got a position alarm. The result was alarm databases with thousands of alarms, many of them poorly rationalized.
The consequences were measurable and serious:
- Operators acknowledging dozens of alarms per shift without reading them
- Critical alarms hidden in the noise of routine notifications
- Alarm floods during process upsets that overwhelmed operator capacity
- Operators normalizing alarm presence rather than treating alarms as exceptional events
- Critical safety events that traced back to operators having tuned out the alarm system
Several major industrial incidents in the late 1990s and 2000s — including the Texas City refinery disaster in 2005 — identified alarm management failures as contributing factors. The investigations consistently pointed to alarm systems that had become noise rather than signal, and to operators who had lost the ability to distinguish important alarms from routine ones.
The research and development that drove ISA-18.2.
The Abnormal Situation Management Consortium (ASM Consortium), formed in 1994 by Honeywell, Amoco, Shell, Mobil, BP, and others, conducted extensive research into operator effectiveness during abnormal situations. The findings consistently identified alarm management as a critical factor.
The Engineering Equipment and Materials Users’ Association (EEMUA) published Publication 191 (Alarm Systems: A Guide to Design, Management and Procurement) in 1999, providing early guidance on what good alarm management looked like.
In 2003, the ISA standards committee began work on what became ANSI/ISA-18.2-2009. The standard was revised in 2016 to incorporate six years of industry experience, and was adopted internationally as IEC 62682. It is now referenced as recognized and generally accepted good engineering practice by OSHA in the United States and similar bodies internationally.
What the standard actually requires.
The standard establishes a ten-stage lifecycle per the official ISA-18.2 standard and requires that organizations develop:
- A documented Alarm Philosophy governing all alarm design at the facility
- A rationalization process for evaluating every alarm against the philosophy
- Performance metrics for monitoring alarm system health
- A management of change process for alarm modifications
- Periodic audit to verify ongoing compliance
The standard doesn’t prescribe specific alarm setpoints or priorities — those are facility-specific decisions captured in the Alarm Philosophy. What what the standard prescribes is the discipline that produces an effective alarm system.
For broader DCS context, see our What Is a DCS cornerstone guide.
The Ten-Stage Alarm Management Lifecycle
The standard defines a complete lifecycle that runs from initial design through decommissioning. The ten stages work together as a continuous improvement loop.
Stage 1 — Philosophy.
The Alarm Philosophy document is the foundation. It establishes alarm design principles, priority definitions, performance targets, rationalization criteria, and management of change requirements. The philosophy is created during initial design and reviewed periodically.
Stage 2 — Identification.
Identification produces the master list of candidate alarms — every condition that might reasonably generate an alarm. This list typically comes from cause-and-effect matrices, HAZOP studies, process design documents, and operator interviews. The identification list is broad; rationalization will narrow it.
Stage 3 — Rationalization.
Rationalization is the most labor-intensive stage. Every candidate alarm is evaluated against the philosophy criteria. Each surviving alarm receives a documented justification, priority assignment, setpoint, classification, and operator response procedure. This is the workshop process I mentioned in the opening that took weeks on the African project.
Stage 4 — Detailed Design.
Detailed design translates rationalized alarms into actual configuration. Setpoints, deadbands, time delays, suppression logic, alarm group assignments — all designed per the rationalization output and the philosophy requirements.
Stage 5 — Implementation.
Implementation loads the detailed design into the DCS. This is where the alarms get configured in Honeywell Experion, Yokogawa CENTUM, Emerson DeltaV, or whichever platform is in use. Implementation includes testing, validation, and operator training before go-live.
Stage 6 — Operation.
The alarm system is in active use. Operators respond to alarms, the system runs as designed, day-to-day operations continue. This is the longest stage in the lifecycle.
Stage 7 — Maintenance.
Alarms that need recalibration, suppression updates, or temporary disablement are handled through maintenance processes. Out-of-service alarms require formal tracking.
Stage 8 — Monitoring & Assessment.
Performance metrics are continuously monitored — alarm rate, alarm flood occurrence, alarm acknowledgment time, top contributors, chattering alarms. Assessment identifies improvement opportunities feeding back into earlier stages.
Stage 9 — Management of Change (MOC).
Any alarm modification requires formal management of change — impact assessment, rationalization review, validation, documentation update. Casual changes without MOC are how alarm systems degrade over time.
Stage 10 — Audit.
Periodic audit verifies the alarm system continues to comply with the philosophy and performance targets. Audit findings feed back into philosophy updates or rationalization passes.
The lifecycle approach (similar in structure to the functional safety lifecycle from IEC 61511) is why alarm management can’t be a one-time engineering deliverable. Plants evolve, processes change, equipment is added — the alarm system must evolve with them through this lifecycle discipline.
The Alarm Philosophy Document
The Alarm Philosophy is the foundational deliverable that governs every alarm design decision at the facility. A well-written philosophy is typically 30-80 pages and addresses every aspect of how alarms work at this specific plant.
What the philosophy covers:
- Alarm definition — what qualifies as an alarm at this facility (vs information, status, or diagnostic)
- Priority definitions — Critical, High, Medium, Low with explicit criteria for each
- Alarm classes — process, safety, equipment, environmental, security, with class-specific rules
- Response time expectations — how quickly operators should respond to each priority
- Performance targets — alarm rate per operator, flood thresholds, key performance indicators
- Rationalization criteria — explicit rules for accepting or rejecting candidate alarms
- Suppression logic rules — when alarms may be suppressed (equipment out of service, startup mode, etc.)
- Operator workload limits — maximum sustainable alarm rate per operator
- HMI display rules — how alarms appear on operator screens (references ISA-101 HMI Design)
- Management of change requirements — process for any alarm modification
- Roles and responsibilities — who owns alarm design, who reviews changes, who audits performance
Why the philosophy must be facility-specific.
A common mistake is using a template philosophy without facility-specific tailoring. The right priority assignments for a refinery differ from a pharmaceutical batch plant. The right alarm classes for an LNG facility differ from a power station. The operator response time achievable on a complex unit differs from a simple skid system.
On the oil and gas mega-project in Asia where I currently work, the Alarm Philosophy went through multiple revisions during design — operations input changed priority definitions, process safety input refined classification rules, the SIS engineering team aligned alarm classes with safety instrumented function requirements. The philosophy that emerged was specific to the facility’s operational reality, not a generic template.
The Rationalization Process
Rationalization is where the philosophy meets reality. Every candidate alarm gets evaluated against the philosophy criteria; the surviving alarms become the actual configured alarms.
The seven-step rationalization workflow:
- Compile candidate alarm list from process design, HAZOP, cause-and-effect matrices
- Evaluate against philosophy — does this condition meet the facility’s definition of an alarm?
- Determine priority — Critical, High, Medium, or Low per philosophy criteria
- Set parameters — setpoint, deadband, time delay, alarm class
- Define operator response — what should the operator do when this alarm activates?
- Document rationalization rationale — why this alarm exists, why it’s priority X, what action to take
- Approve and release for detailed design — facility approval before implementation
What rationalization workshops look like.
A typical rationalization workshop has 4-6 participants — operations representative, process engineering, automation engineering, process safety, sometimes vendor specialist, sometimes management. The team works through alarms systematically — often 30-50 alarms per day depending on complexity.
Each alarm gets discussion: Why does this alarm exist? What’s the worst-case consequence if it’s missed? What can the operator actually do about it? How long does the operator have to respond? Is this alarm duplicative with another? Should it be suppressed when other equipment is offline?
I’ve sat in these workshops for weeks at a time. They’re tedious. They’re also where alarm system quality is actually built. Without rigorous rationalization, you get an alarm database that’s never been honestly questioned — and that’s where alarm floods and operator desensitization come from.
Rationalization output.
Each rationalized alarm has documented attributes:
- Alarm tag and description
- Priority and class
- Setpoint and deadband
- Time delay (filter time before activating)
- Operator response procedure
- Suppression conditions (when this alarm should be hidden)
- Documented justification for the alarm
- Approval signature from operations and engineering
This documentation becomes the master record of the alarm system. Any future change requires updating the rationalization record.
Alarm Priorities Explained
The standard requires alarm priorities with defined criteria. Most facilities use four priorities, though some use three or five depending on philosophy.
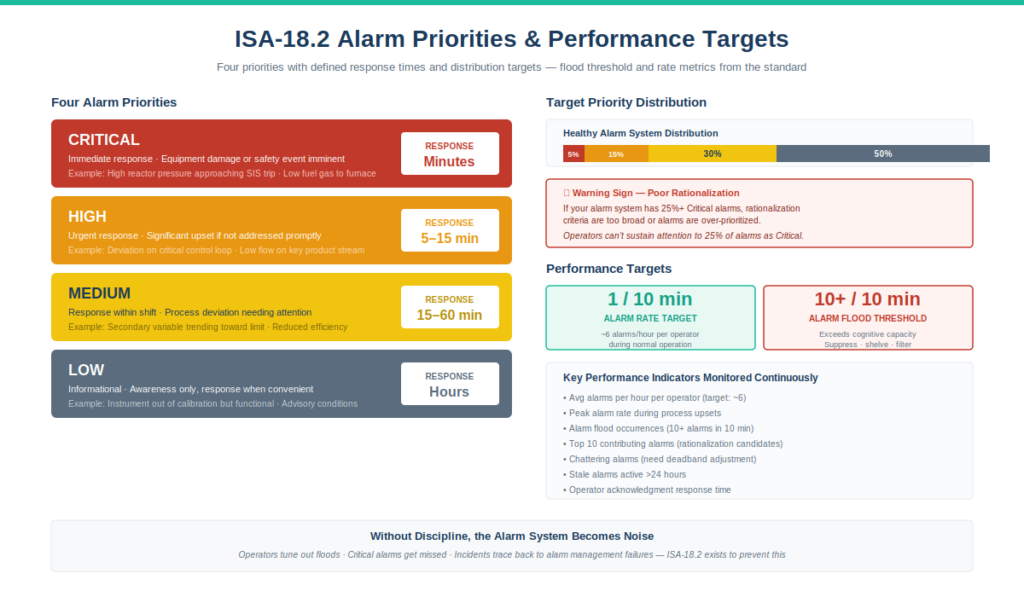
Critical (sometimes called Emergency) — immediate response required.
The most severe priority. Indicates conditions where operator inaction leads to immediate severe consequences — equipment damage, safety event, environmental release, regulatory violation. Response time is measured in minutes or less. Example: high reactor pressure approaching shutdown setpoint, low fuel gas pressure on a furnace heading toward flameout, high level on a vessel approaching overfill.
High — urgent response required.
Significant process upset or equipment damage potential if not addressed promptly. Response time typically 5-15 minutes. Example: deviation from target temperature on a critical control loop, low flow on a key product stream, motor amperage approaching trip setpoint.
Medium — response required within shift.
Process deviation that needs operator attention but doesn’t require immediate action. Response time typically 15-60 minutes. Example: secondary process variable trending toward limit, equipment running but with reduced efficiency, environmental parameter approaching upper limit.
Low — informational, response when convenient.
Conditions that warrant operator awareness but no immediate action. Response time can be hours. Example: instrument out of calibration but still functional, secondary equipment in degraded but operating mode, advisory conditions.
Priority distribution targets.
A well-rationalized alarm system has skewed priority distribution. Typical targets from industry data:
- Critical: ~5% of alarms
- High: ~15% of alarms
- Medium: ~30% of alarms
- Low: ~50% of alarms
If your alarm system has 25% Critical alarms, something is wrong with rationalization — either alarms are over-prioritized or the philosophy criteria for Critical are too broad. Operators can’t sustain attention to 25% of all alarms as Critical.
ISA-18.2 Performance Metrics
The standard defines performance metrics that allow continuous monitoring of alarm system health. These metrics turn alarm management from anecdotal (“it feels like we have too many alarms”) into measurable (“our alarm rate exceeded target by 40% last month”).
Key performance indicators:
- Average alarms per hour per operator — target: ~6 alarms/hour (1 per 10 minutes) during normal operation
- Alarms per 10 minutes — target: ≤1 (this is the most cited ISA-18.2 metric)
- Peak alarm rate — short bursts above target are expected; sustained excursions indicate problems
- Alarm flood occurrences — flood = 10+ alarms in 10 minutes; target: rare
- Top 10 contributing alarms — the alarms generating the most activations; candidates for rationalization
- Chattering alarms — alarms activating repeatedly without operator intervention; need deadband adjustment
- Stale alarms — alarms active for >24 hours; usually need acknowledgment process review
- Standing alarms — alarms acknowledged but still active; should be cleared or suppressed
- Alarms suppressed by design — alarms that should be hidden during specific operating modes
- Operator response time — time from alarm activation to acknowledgment
The “1 alarm per 10 minutes” target.
This number comes from human factors research on operator workload sustainability. An average operator monitoring a process can effectively respond to about 6 alarms per hour as a steady state. Higher sustained rates lead to alarm tolerance — operators stop reading individual alarms and start treating them as background noise.
The target is an average over a representative period (typically a month) during normal operation. Brief excursions during upsets are expected and acceptable; sustained excursions during normal operation indicate the alarm system needs rationalization.
Alarm flood handling.
An alarm flood (10+ alarms in 10 minutes) overwhelms operator cognitive capacity. Standard responses to alarm floods include:
- First-up alarm display — clearly identifying which alarm came first to help root cause analysis
- Cause-and-effect-based suppression — when one alarm activates, related downstream alarms are temporarily suppressed
- Alarm shelving — operators can temporarily shelve known nuisance alarms during specific situations
- Dynamic alarm filtering — alarms appropriate to specific operating modes only
On the offshore brownfield in Africa, post-rationalization, alarm flood events decreased dramatically. The alarm management discipline genuinely changed operator effectiveness.
How ISA-18.2 Integrates with ISA-101 HMI Design
The alarm management standard and ISA-101 are explicitly companion standards. They were developed by overlapping ISA committees specifically to work together. Implementing one without the other produces inferior results.
The division of responsibilities.
- ISA-18.2 governs the alarm system itself — which alarms exist, what priorities they have, what response is expected, performance targets
- ISA-101 governs how alarms appear on operator displays — color usage, alarm summary banners, embedded indicators, navigation, situational awareness
Why integration matters.
A perfectly rationalized alarm system with poorly designed HMI displays delivers minimal benefit. The operator sees the right alarms but in a format that obscures urgency. Conversely, an excellent ISA-101 HMI with a poorly rationalized alarm system overwhelms the operator with notifications that look beautifully formatted but are still overwhelming.
Both standards must be implemented in parallel. The Alarm Philosophy must specify how alarms appear on HMI screens (which references ISA-101 conventions); the HMI Style Guide must specify how alarm priorities are visually distinguished (which depends on ISA-18.2 priority definitions).
On every project I’ve worked on with proper standards implementation, the alarm management and HMI design teams worked together throughout the project. Workshops included both teams. Reviews verified that alarms looked appropriate on actual HMI screens at all priorities. Operators saw integrated improvement, not two separate engineering initiatives.
For the complete treatment of HMI design, see our ISA-101 HMI Design guide.
Implementation on Major DCS Platforms
Every major DCS platform supports the standard, with vendor-specific tools and approaches.
Honeywell Experion PKS.
Experion provides native alarm management capabilities including alarm priorities, classes, summary displays, shelving, and performance reporting. Experion supports advanced alarm features through optional packages (Honeywell Alarm Configuration Manager, Alarm Performance Monitoring). Integration with the Experion Station HMI ensures alarms appear consistently across operator displays.
For broader Experion context, see our Honeywell Experion PKS architecture guide.
Yokogawa CENTUM VP.
CENTUM provides comprehensive alarm management through the FCS and HIS, with native support for priorities, classes, suppression, and shelving. Yokogawa’s Exaopc and Exaquantum products provide additional alarm analytics and performance reporting capabilities.
For broader CENTUM context, see our Yokogawa CENTUM VP architecture guide.
Emerson DeltaV.
DeltaV provides alarm management through native DeltaV functionality plus add-on alarm management products. DeltaV’s alarm philosophy implementation is supported through their alarm configuration tools and integrated reporting.
For broader DeltaV context, see our Emerson DeltaV architecture guide.
ABB 800xA and Siemens PCS 7.
Both platforms support full alarm management implementation through their respective alarm subsystems. ABB’s alarm performance is integrated into 800xA’s information management; Siemens provides alarm management through WinCC OS with PCS 7-specific tools.
Third-party alarm management tools.
Several third-party products provide alarm management capabilities that integrate with multiple DCS platforms — exida, PAS, Trinity Technologies, ProSys. These tools are often used for cross-platform consistency on multi-vendor facilities or where DCS-native alarm management capabilities are insufficient.
Cross-platform reality.
The implementation approach is similar across platforms: develop the philosophy, conduct rationalization, configure alarms per rationalization output, integrate with HMI per ISA-101, monitor performance against targets. Vendor tools differ; the underlying discipline is the same.
For the broader architectural decision of platform selection, see our DCS vs SCADA vs PLC capstone guide.
Common Alarm Management Mistakes I’ve Seen
After working with alarm management across multiple platforms and project phases, here are the recurring mistakes:
Skipping the philosophy and going straight to alarm configuration. Without a documented philosophy, every engineer makes their own implicit philosophy decisions. The alarm database becomes a patchwork of different design approaches with no consistent logic. Rationalization can recover some of this, but the upfront philosophy investment is much cheaper than post-hoc cleanup.
Treating rationalization as one-time work. Plants evolve. Equipment changes. Process modifications happen. Without periodic rationalization passes (every few years minimum), the alarm system drifts away from its original design intent. Continuous management of change can slow the drift but doesn’t replace periodic comprehensive reviews.
Setting overly conservative alarm setpoints. Engineers under pressure to be safe set alarm setpoints close to normal operating values “just in case.” The result is alarms that activate during normal process variation. Operators learn to ignore them. Setpoints should be set at points where action is genuinely required, with appropriate deadbands and time delays.
Ignoring chattering alarms. Alarms that activate and clear repeatedly within minutes indicate setpoint, deadband, or time delay problems. They’re not “operator nuisance” — they’re system configuration problems. Fix them at the configuration level rather than tolerating them.
Failing to integrate with HMI design. Alarm management and ISA-101 HMI design are companion standards. Implementing one without the other delivers minimal benefit. Coordination must be continuous throughout the project.
Underestimating rationalization workshop time. Allocating two days for an alarm rationalization workshop on a 5,000-alarm system is unrealistic. Real workshops process 30-50 alarms per day at reasonable quality. A 5,000-alarm rationalization is months of workshop time. Budget appropriately.
Forgetting that alarms must drive action. ISA-18.2 defines an alarm as a condition requiring operator action. If an alarm doesn’t have a defined response, it shouldn’t be an alarm — it should be a notification, status, or diagnostic. The discipline of asking “what should the operator do?” eliminates many candidate alarms during rationalization.
Ignoring management of change after deployment. Engineering and operations often modify alarms in the field — adjust a setpoint, add a delay, change a priority. Without MOC, these changes accumulate undocumented. After a few years, the actual alarm configuration diverges from the rationalization record, and rationalization quality degrades.
Treating alarm floods as inevitable. Some engineering cultures accept floods as “what happens during upsets.” Modern alarm management can substantially reduce flood occurrences through cause-and-effect suppression, dynamic alarm filtering, and first-up alarm displays. Floods don’t have to be the norm.
Skipping performance metrics monitoring. Without continuous metrics, you don’t know whether the alarm system is performing per the philosophy targets. Monthly performance reports should be standard. Excursions should drive specific corrective actions.
Frequently Asked Questions
What is ISA-18.2?
ISA-18.2 (ANSI/ISA-18.2-2016) is the international standard for management of alarm systems in the process industries. It defines a ten-stage lifecycle for designing, implementing, operating, and maintaining alarm systems with the goal of preventing alarm floods, reducing nuisance alarms, and ensuring effective operator response to abnormal situations.
What does ISA-18.2 require?
The standard requires a documented Alarm Philosophy, a rigorous rationalization process, defined alarm priorities with response time expectations, performance metrics with targets, management of change procedures for alarm modifications, and periodic audits to verify ongoing compliance.
What is alarm rationalization?
Rationalization is the process of systematically reviewing every candidate alarm against the Alarm Philosophy criteria. The team evaluates whether the alarm is genuinely needed, determines its priority, sets parameters (setpoint, deadband, time delay), defines the operator response, and documents the rationale. Typical workshops process 30-50 alarms per day.
What are the alarm priorities?
Most facilities define four priorities under ISA-18.2: Critical (immediate response, minutes), High (urgent response, 5-15 minutes), Medium (response within shift, 15-60 minutes), and Low (informational, response when convenient). The specific definitions are documented in the Alarm Philosophy.
What is the alarm rate target?
The most commonly cited target is approximately 1 alarm per 10 minutes per operator (6 alarms per hour) during normal operation, averaged over a representative period. This number comes from human factors research on sustainable operator workload.
What is an alarm flood?
Alarm flood is defined as 10 or more alarms in a 10-minute period — a rate that exceeds operator cognitive capacity to process individual alarms. Flood events typically occur during process upsets, equipment trips, or cascading failures. the standard includes specific techniques (cause-and-effect suppression, shelving, dynamic filtering) for managing alarm floods.
How does alarm management relate to ISA-101?
ISA-18.2 governs the alarm system (which alarms exist, priorities, response expectations); ISA-101 governs how alarms appear on operator HMI displays. The two standards are explicit companions — both must be implemented together for either to deliver its potential benefit.
Is the standard the same as IEC 62682?
Yes — IEC 62682 is the international adoption of ANSI/ISA-18.2-2016. The technical content is the same. References to either standard generally refer to the same requirements.
Is alarm management compliance mandatory?
The standard is voluntary in most jurisdictions but is widely referenced as recognized and generally accepted good engineering practice. OSHA references it for process safety management compliance. Many regulated industries (pharmaceutical FDA compliance, certain chemical operations) expect or require compliance.
How long does alarm rationalization take?
For a typical mid-size process facility with 2,000-5,000 alarms, full rationalization runs several weeks to several months of workshop time depending on facility complexity and workshop frequency. Greenfield rationalization happens during design; brownfield rationalization typically targets the highest-impact alarms first then expands.
Conclusion
ISA-18.2 is the foundation discipline that determines whether the alarm system actually helps operators during the abnormal situations when help matters most, or becomes part of the problem by overwhelming them with noise. The standard exists because the industry’s pre-2009 alarm practices had measurably contributed to operator effectiveness failures and to specific incidents.
The most important practical truths about alarm management:
- The Alarm Philosophy is the foundational document; skipping it produces unmanageable alarm databases
- Rationalization is the most labor-intensive but most valuable stage — every alarm must be honestly questioned
- Alarm priorities must follow the philosophy criteria, not engineer convenience
- Performance metrics turn alarm management from anecdotal into measurable
- Alarm flooding is preventable with proper rationalization and suppression design
- ISA-18.2 and ISA-101 are companion standards — implement both together
- The lifecycle approach means alarm management is ongoing work, not a one-time project
On every project I’ve worked on with proper alarm management implementation, the operator experience has been measurably different from facilities without it. Alarm rates settle at sustainable levels. Floods become rare events rather than weekly occurrences. Operators trust the alarm system and respond appropriately when alarms activate. The investment in philosophy, rationalization, and ongoing performance monitoring pays back continuously through better operator effectiveness and incident prevention.
If you’re approaching an alarm management initiative, resist the temptation to skip directly to detailed alarm configuration. Invest in the philosophy first. Rigorously rationalize against the philosophy criteria. Integrate alarm design with ISA-101 HMI design. Monitor performance against targets. And recognize that alarm management is a discipline that continues over the entire life of the plant, not a project deliverable that gets signed off and forgotten.
For broader DCS context, see our What Is a DCS cornerstone guide. For the companion HMI design standard, see our ISA-101 HMI Design guide. For platform-specific implementation context, see our Honeywell Experion PKS architecture guide, Yokogawa CENTUM VP architecture guide, and Emerson DeltaV architecture guide. For the broader architectural decision of where alarm management fits within an overall control system, see our DCS vs SCADA vs PLC capstone guide.
For the companion standard governing how the alarm management layer connects to enterprise systems above it — including the Purdue Reference Model, Level 3-4 interface, and how alarm performance data flows upward to MES and ERP — see our ISA-95 Enterprise Integration guide.
About the Author
Daniel Reed is an Instrument and Controls Engineer with 14+ years of oil and gas EPC experience across onshore and offshore projects in Asia and Africa. He currently works as a client-side I&C completion engineer on a large oil and gas mega-project in Asia, where he has been involved with Honeywell Experion PKS and Safety Manager since 2018.
His earlier work covered Yokogawa CENTUM and Triconex SIS on an offshore brownfield in Africa (2015-2018), and Yokogawa CENTUM and ProSafe-RS on a gas-to-liquids facility in Africa. His focus is engineering deliverable review, control and safety system commissioning, HAZOP/SIL/SIF participation, FAT/SAT execution, alarm management and HMI design to industry standards across multiple DCS platforms, and vendor coordination across Honeywell, Yokogawa, Triconex, Allen-Bradley, and Siemens platforms.